Understanding Modeling Terminology
Untangling the vocabulary of data and information modeling
The Terminology Jungle
If you've spent any time in the data modeling space, you've likely encountered a bewildering array of terms: data model, conceptual model, logical model, physical model, concept model, semantic model, information model, fact-oriented model. These terms are sometimes used interchangeably, sometimes mean completely different things depending on who's speaking, and often cause more confusion than clarity.
This article aims to untangle these terms, trace their historical origins, and explain why the distinctions matter—especially as organizations grapple with integrating systems across departments and making sense of decades of accumulated data.
AI Needs More Than a Glossary
The semantic grounding problem that glossaries, ontologies, and vector databases can't solve on their own
You've probably noticed the pattern by now. You feed your data to an AI, ask it a question, and get an answer that's technically plausible but semantically wrong. The AI confuses "customer" in your sales system with "client" in your support tickets. It hallucinates relationships between fields that share similar names but mean entirely different things. Ask the same question twice with slightly different phrasing, and you get contradictory responses.
Welcome to semantic drift—the silent killer of AI reliability.
Understanding before Data
Why Data Modeling Must Start with Human Understanding
A Conversation on Information Modeling, AI, and the Real Challenge of Enterprise DataIn a recent conversation with a data professional exploring database development tools, Marco Wobben offered a perspective that cuts straight through the noise surrounding modern data projects. With over 25 years in information modeling, he's seen the same pattern repeat: technology advances rapidly, yet the biggest failures trace back to something very human.
Beyond the Technical
"Why Data Modeling Success Hinges on Communication, Not Code"
Based on a conversation between data modeling experts Remco Broekmans (ELM), Marco Wobben (CaseTalk), and host Joe Reis
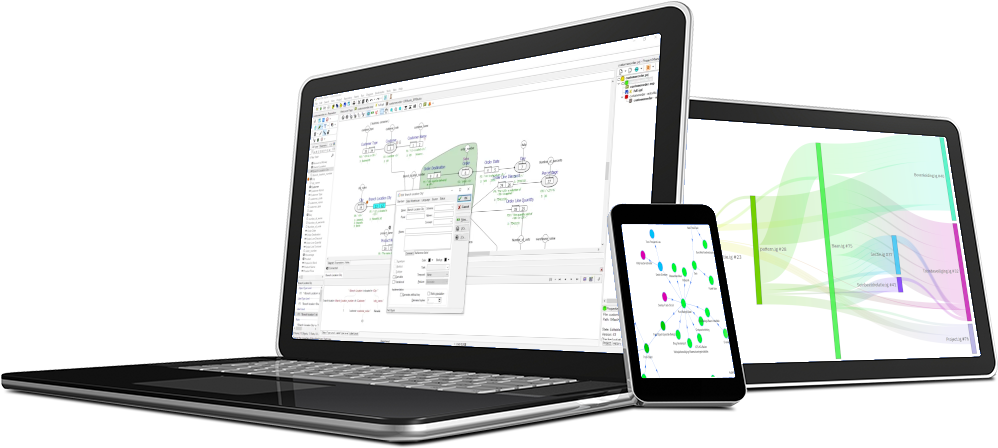
Data Explorer
CaseTalk’s Data Explorer offers powerful functionality that goes beyond traditional information modeling. While classical modeling focuses on conducting interviews with domain experts—capturing their knowledge and requirements in natural language—there are situations where access to live organizational data can significantly enhance the process. This is where the Data Explorer becomes invaluable.
The Illusion of 'Data-Driven'
Why Grit, Grounded Vision, and FCO-IM Are the Real Game Changers
In the modern push for digital transformation, countless organizations have embraced the rallying cries of "data-driven decision-making" and the "AI revolution." Buzzwords echo in boardrooms. Pilot projects flourish. Consultants profit. Yet, somewhere between the vision decks and the dashboards, the people on the work floor—the ones who keep operations moving—are forgotten. And so is the fundamental truth: sustainable change starts with clarity, communication, and commitment.
Population on a Map
Whenever we post updates of CaseTalk on social media, some experts take these a step further. I love seeing those kinds of responses, for they are making me think outside the box, and add unique new features I never dreamed about. One of these comments was placed at a post about integrating the webbrowser in CaseTalk to integrate the web into the modeling workbench.
This specific comment suggested integrating Google Maps or OpenStreetMap into the model. It would allow example population, to be plotted onto a map, or have custom attribute annotations to indicate where the model element occurred.
After having given this idea enough time to ripen, I decided to combine the so-called complex type and Maps into one. Let me explain.
News
Scheduled
-
3 days - Fact Based Modeling with CaseTalk
February 18, 2026 9:00 am