These articles will show usage of CaseTalk, demonstrating how to refactor your model, or model very specific facts. If you have questions which remain unanswered please ask us. Your question may lead to an article on our website for the benefit of you and others.
Linking tables
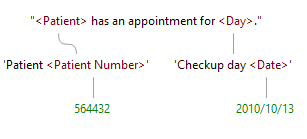
In our often used example about blood pressure, we wanted to add a fact for the appointments our patients need to make beforehand.
The fact expressions are pretty straightforward and the rules are similarly simple. The fact "Patient 564432 has an appointment for a checkup on 2010/10/13" contains a structure similarly straight forward:
Titanic Data (Model)
On many conferences where AI, ML or data science is mentioned, a simple dataset is used to underpin the storyline of the sessions. The Titanic dataset is such a relatively small and simple example. Until now a Fact Oriented Model was absent. So, let's see how we can build one out of the dataset by verbalizing it.
Modeling a catalog
Modeling the communication about the data as expressed by domain experts can clash with technical oriented viewpoints. For instance the world of reference data and catalogs which might use codes, versus the actual values that bear meaning to the business. This article explores how an example case of preferred pronouns can unite people with different viewpoints.
Supporting ER/Studio
Idera ER/Studio is a data modeling tool with a modern interface, supporting a wide range of databases. CaseTalk supports the logical data models using a script generator. Generated script can simply be executed inside ER/Studio in order to have the logical model automatically build for you.
Refactor your Model
Though the FCO-IM method guarantees an higher accuracy for your information model, which leads to less rework after initial release and usage, it also requires you to put in a lot of thinking effort from the very beginning. And though this approach is very supportive for incremental work, beginners tend to think of it as tiresome.
Scheduled
-
3 days - Fact Based Modeling with CaseTalk
February 18, 2026 9:00 am